Best practices for integrators
Interested in integrating with the GitHub platform? You’re in good company. This guide will help you build an app that provides the best experience for your users and ensure that it’s reliably interacting with the API.
- Secure payloads delivered from GitHub
- Favor asynchronous work over synchronous
- Use appropriate HTTP status codes when responding to GitHub
- Provide as much information as possible to the user
- Follow any redirects that the API sends you
- Don’t manually parse URLs
- Dealing with rate limits
- Dealing with API errors
Secure payloads delivered from GitHub
It’s very important that you secure the payloads sent from GitHub. Although no personal information (like passwords) is ever transmitted in a payload, leaking any information is not good. Some information that might be sensitive include committer email address or the names of private repositories.
There are three steps you can take to secure receipt of payloads delivered by GitHub:
- Ensure that your receiving server is on an HTTPS connection. By default, GitHub will verify SSL certificates when delivering payloads.
- You can whitelist the IP address we use when delivering hooks to your server. To ensure that you’re always checking the right IP address, you can use the
/metaendpoint to find the address we use. - Provide a secret token to ensure payloads are definitely coming from GitHub. By enforcing a secret token, you’re ensuring that any data received by your server is absolutely coming from GitHub. Ideally, you should provide a different secret token per user of your service. That way, if one token is compromised, no other user would be affected.
Favor asynchronous work over synchronous
GitHub expects that integrations respond within thirty seconds of receiving the webhook payload. If your service takes longer than that to complete, then GitHub terminates the connection and the payload is lost.
Since it’s impossible to predict how fast your service will complete, you should do all of “the real work” in a background job. Resque (for Ruby), RQ (for Python), or RabbitMQ (for Java) are examples of libraries that can handle queuing and processing of background jobs.
Note that even with a background job running, GitHub still expects your server to respond within thirty seconds. Your server simply needs to acknowledge that it received the payload by sending some sort of response. It’s critical that your service to performs any validations on a payload as soon as possible, so that you can accurately report whether your server will continue with the request or not.
Use appropriate HTTP status codes when responding to GitHub
Every webhook has its own “Recent Deliveries” section, which lists whether a deployment was successful or not.
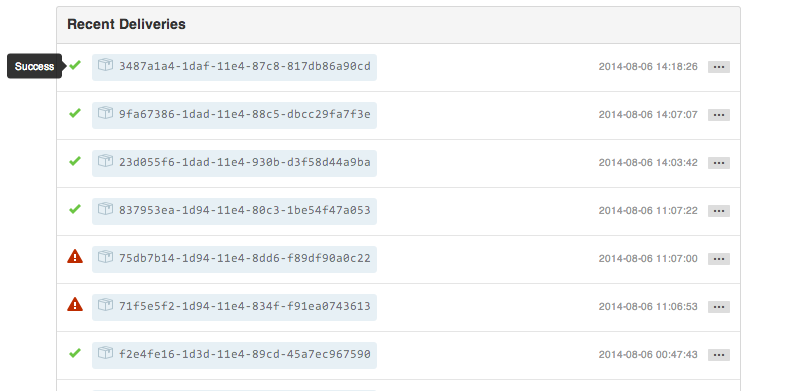
You should make use of proper HTTP status codes in order to inform users. You can use codes like 201 or 202 to acknowledge receipt of payload that won’t be processed (for example, a payload delivered by a branch that’s not the default). Reserve the 500 error code for catastrophic failures.
Provide as much information as possible to the user
Users can dig into the server responses you send back to GitHub. Ensure that your messages are clear and informative.
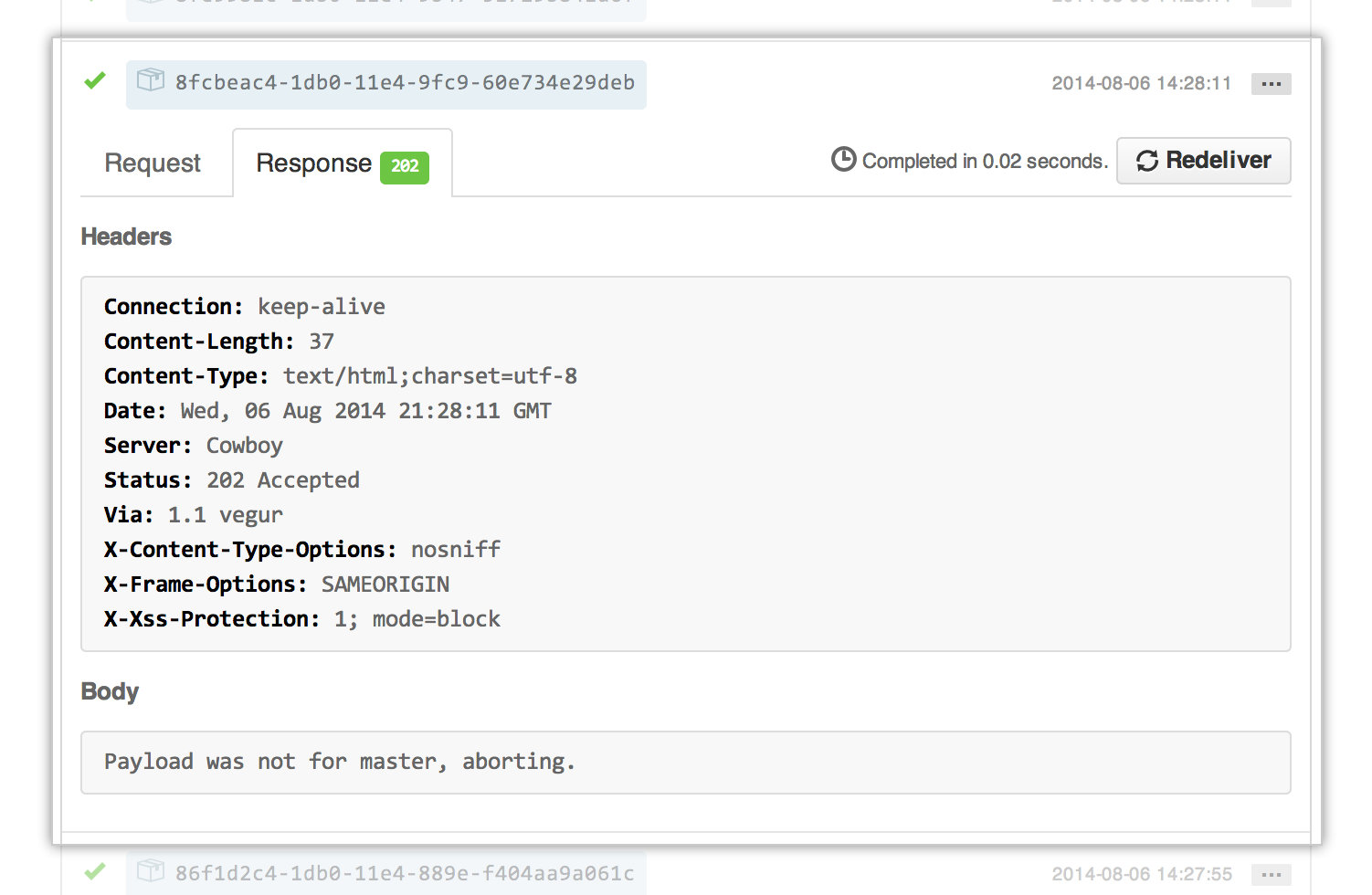
Follow any redirects that the API sends you
GitHub is explicit in telling you when a resource has moved by providing a redirect status code. You should follow these redirections. Every redirect response sets the Location header with the new URI to go to. If you receive a redirect, it’s best to update your code to follow the new URI, in case you’re requesting a deprecated path that we might remove.
We’ve provided a list of HTTP status codes to watch out for when designing your app to follow redirects.
Don’t manually parse URLs
Often, API responses contain data in the form of URLs. For example, when requesting a repository, we’ll send a key called clone_url with a URL you can use to clone the repository.
For the stability of your app, you shouldn’t try to parse this data or try to guess and construct the format of future URLs. Your app is liable to break if we decide to change the URL.
For example, when working with paginated results, it’s often tempting to construct URLs that append ?page=<number> to the end. Avoid that temptation. Our guide on pagination offers some safe tips on dependably following paginated results.
Dealing with rate limits
The GitHub API rate limit ensures that the API is fast and available for everyone.
If you hit a rate limit, it’s expected that you back off from making requests and try again later when you’re permitted to do so. Failure to do so may result in the banning of your app.
You can always check your rate limit status at any time. Checking your rate limit incurs no cost against your rate limit.
Dealing with API errors
Although your code would never introduce a bug, you may find that you’ve encountered successive errors when trying to access the API.
Rather than ignore repeated 4xx and 5xx status codes, you should ensure that you’re correctly interacting with the API. For example, if an endpoint requests a string and you’re passing it a numeric value, you’re going to receive a 5xx validation error, and your call won’t succeed. Similarly, attempting to access an unauthorized or nonexistent endpoint will result in a 4xx error.
Intentionally ignoring repeated validation errors may result in the suspension of your app for abuse.
